DATA CENTRE
Broadcom’s Tomahawk 6 and the Future of AI Data Center Cabling


Broadcom’s new 102.4 Tbps switch chip marks a major leap in data center networking, addressing bandwidth and latency bottlenecks as AI workloads scale. High-speed, low-latency infrastructure is now essential.

World’s first 102.4 Tbps switch chip
In early June, Broadcom made headlines with the release of its next-generation switch chip series—Tomahawk 6—the world’s first switch chip offering 102.4 Tbps (terabits per second) of bandwidth, doubling the capacity of today’s mainstream 51.2 Tbps Ethernet data center switches. Designed specifically for AI data centers, Tomahawk 6 enhances scale-up/scale-out architectures and incorporates 100G/200G SerDes (Serializer/Deserializer) and CPO (Co-Packaged Optics) technologies to meet the ever-growing demands of AI clusters, including those with 100,000+ XPUs.
With the recent surge in large-scale AI model launches, the need for massive-scale, high-performance infrastructure is becoming more urgent than ever. Network bandwidth and low latency have now become the primary bottlenecks in scaling AI data centers.

Redefining Cabling in the AI Era
Tomahawk 6 significantly eases network bandwidth pressure. Equipped with 200G SerDes, it delivers 512 channels at 200Gbps, and also offers a 1024 x 100G version to support legacy 100G SerDes infrastructure. For massive AI cluster networking, the chip’s unified Ethernet architecture supports expansion from 512 up to 100K XPUs.

Image: TH6 enables efficient scale-up networking for 512 XPUs (Source: Broadcom)
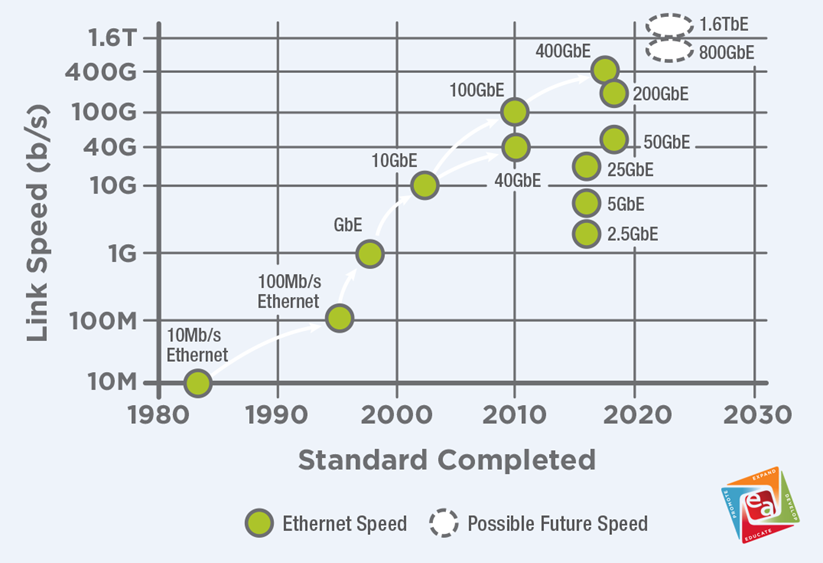
As a switch chip based on 200G SerDes, Tomahawk 6 sets a clear path toward 1.6T networking, an upgrade from today’s 400G/800G deployments. It also marks the beginning of a new era in cabling for AI data centers.
Bandwidth Doubled: Entering the 1.6T Era
AI data center networks differ from traditional ones in two key aspects:
- The demand for extremely high-speed networking.
- The need for ultra-low latency.
Large-scale AI models rely heavily on GPU interconnects, often using RDMA (Remote Direct Memory Access) to minimize CPU usage and boost access efficiency. These interconnects demand extreme bandwidth, and traditional Ethernet no longer suffices. While technologies like InfiniBand (a high-speed, low-latency network standard used in supercomputing) and RoCE (RDMA over Converged Ethernet, which enables fast data transfers over Ethernet) have improved overall networking, even 800G is becoming inadequate. The move to 1.6T is inevitable.
Bandwidth improvement hinges on two key factors:
- The speed of each SerDes channel
- The number of channels
For example, 800G networks can be achieved via:
- 16 x 50G channels
- 8 x 100G channels
- 4 x 200G channels
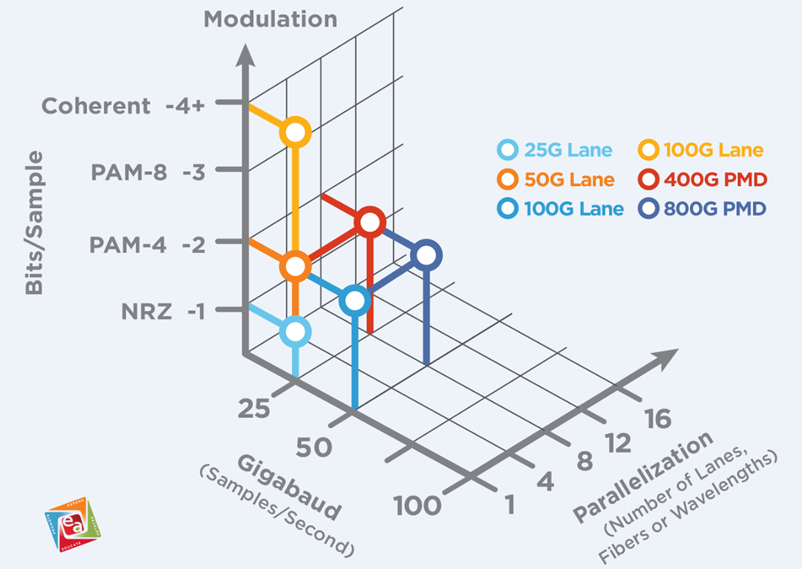
Image: Channel count and 800G relationship (Source: Ethernet Alliance)
A 16-channel solution typically requires two MPO-16 (or MPO-24) connectors for full duplex communication. In contrast, a 4-channel solution needs only one MPO-8/12 connector, significantly simplifying infrastructure. The higher the individual channel speed, the lower the cabling cost and the better the energy efficiency per Gbps.
Lower Latency, Better Scale: Rebuilding the AI Network
Latency is another major hurdle in AI performance. In large data centers, each additional switch layer increases latency. When scaling to 10,000+ GPUs, a three-tier switch architecture is often used, potentially adding up to five switch hops—each introducing latency that far exceeds that of the physical medium (fiber or copper).
Tomahawk 6 enables direct interconnection of up to 512 XPUs, and can scale to support over 100,000 GPUs using a two-tier Clos network—a highly efficient, multi-stage switch architecture commonly used in large-scale data centers—built on 200G links. Compared to traditional three-tier designs, this reduces the number of switch hops by two, significantly lowering latency for hyperscale AI deployments.

Image: Tomahawk 6 enables simplified 2-tier Clos for 100,000+ GPU networks (Source: Broadcom)
New Cabling Trends for AI Data Centers
With growing scale and technical complexity, AI data center cabling must evolve faster than traditional data centers. A flexible, future-ready cabling infrastructure helps users adapt to rapid technological changes without repeatedly overhauling hidden infrastructure.
Standards such as ISO/IEC 11801-5 and TIA 942 emphasize how structured cabling can support ToR (Top-of-Rack), , Spine-Leaf, and Mesh topologies—providing solid groundwork for dynamic and scalable architectures.
Aginode offers its purpose-built LANmark ENSPACE solution for next-gen data centers. With four core advantages, it helps data centers confidently navigate the transition to 800G and 1.6T networking.
Aginode ENSPACE

Powering the AI-Ready Cabling Backbone
- Higher Efficiency
Supports both 8-core and 16-core fiber connections. High-density design maximizes space and boosts data throughput. - Future-Proof Scalability
Compatible with optical modules from 100G to 1.6T, it meets diverse needs and simplifies migration during tech upgrades. - Cost Optimization
Streamlined architecture and simplified installation reduce total cost of ownership (TCO). - Simplified Operations
High-density patch systems reduce cabling complexity and improve maintenance efficiency.
Share this
About the author
