CENTRE DE DONNÉES
Le Tomahawk 6 de Broadcom et l'avenir du câblage des centres de données IA


La nouvelle puce de commutation de Broadcom, d'une capacité de 102,4 Tbps, marque une avancée majeure dans la mise en réseau des centres de données, en s'attaquant aux goulets d'étranglement de la bande passante et de la latence à mesure que les charges de travail de l'intelligence artificielle augmentent. Une infrastructure à haut débit et à faible latence est désormais essentielle.

La première puce de commutation de 102,4 Tbps au monde
Début juin, Broadcom a fait les gros titres avec la sortie de sa série de puces de commutation de nouvelle génération - Tomahawk6 - lapremière puce de commutation au monde offrant une bande passante de 102,4 Tbps (térabits par seconde), doublant ainsi la capacité des commutateurs de centre de données Ethernet grand public actuels de 51,2 Tbps. Conçu spécifiquement pour les centres de données d'IA, Tomahawk 6 améliore les architectures scale-up/scale-out et intègre les technologiesSerDes (Serializer/Deserializer) 100G/200G et CPO (Co-Packaged Optics) pour répondre aux exigences toujours croissantes des clusters d'IA, y compris ceux qui comptent plus de 100 000 XPU.
Avec la récente augmentation du nombre de lancements de modèles d'IA à grande échelle, le besoin d'une infrastructure de haute performance à grande échelle devient plus urgent que jamais. La bande passante du réseau et la faible latence sont devenues les principaux goulets d'étranglement dans les centres de données d'IA à grande échelle.

Redéfinir le câblage à l'ère de l'IA
Tomahawk 6 allège considérablement la pression sur la bande passante du réseau. Équipé d'un SerDes 200G, il fournit 512 canaux à 200Gbps, et propose également une version1024 x 100G pour prendre en charge l'infrastructure SerDes 100G existante. Pour la mise en réseau de clusters d'IA massifs, l'architecture Ethernet unifiée de la puce prend en charge l'expansion de 512 à 100 000 XPU.

Image : Le TH6 permet une mise en réseau efficace et évolutive pour 512 XPU (Source : Broadcom)
En tant que puce de commutation basée sur des SerDes 200G, Tomahawk 6 ouvre une voie claire vers la mise en réseau 1,6T, une amélioration par rapport aux déploiements 400G/800G d'aujourd'hui. Il marque également le début d'une nouvelle ère dans le câblage des centres de données d'intelligence artificielle.
La bande passante a doublé : L'entrée dans l'ère du 1,6T
Les réseaux des centres de données d'IA se distinguent des réseaux traditionnels par deux aspects essentiels :
- La demande de réseaux à très haut débit.
- Le besoin d'une latence ultra-faible.
Les modèles d'IA à grande échelle s'appuient fortement sur des interconnexions GPU, utilisant souvent le RDMA (Remote Direct Memory Access) pour minimiser l'utilisation du CPU et améliorer l'efficacité de l'accès. Ces interconnexions exigent une bande passante extrême, et l'Ethernet traditionnel ne suffit plus. Bien que des technologies comme InfiniBand (une norme de réseau à grande vitesse et à faible latence utilisée dans les superordinateurs) et RoCE (RDMA over Converged Ethernet, qui permet des transferts de données rapides sur Ethernet) aient amélioré la mise en réseau globale, même 800G devient inadéquat. Le passage à 1,6T est inévitable.
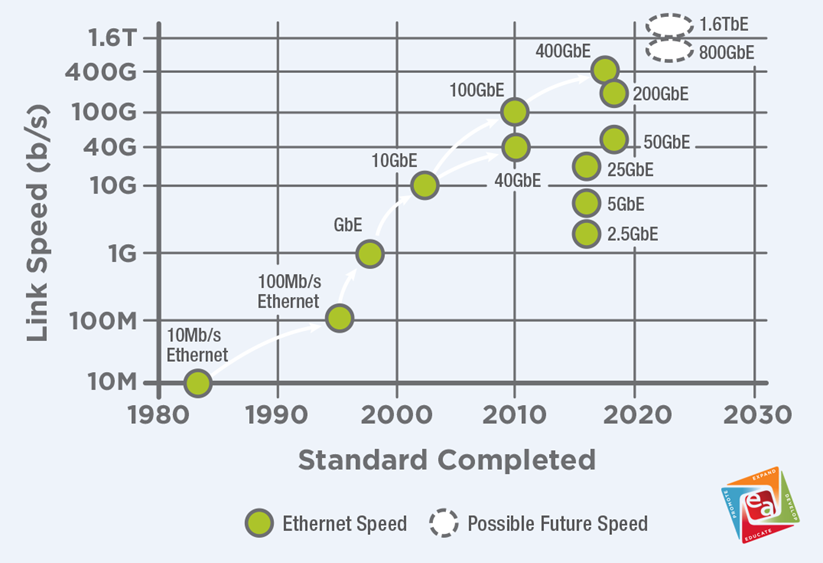
L'amélioration de la bande passante dépend de deux facteurs clés :
- La vitesse de chaque canal SerDes
- Le nombre de canaux
Par exemple, les réseaux 800G peuvent être réalisés via :
- 16 canaux 50G
- 8 canaux 100G
- 4 canaux 200G
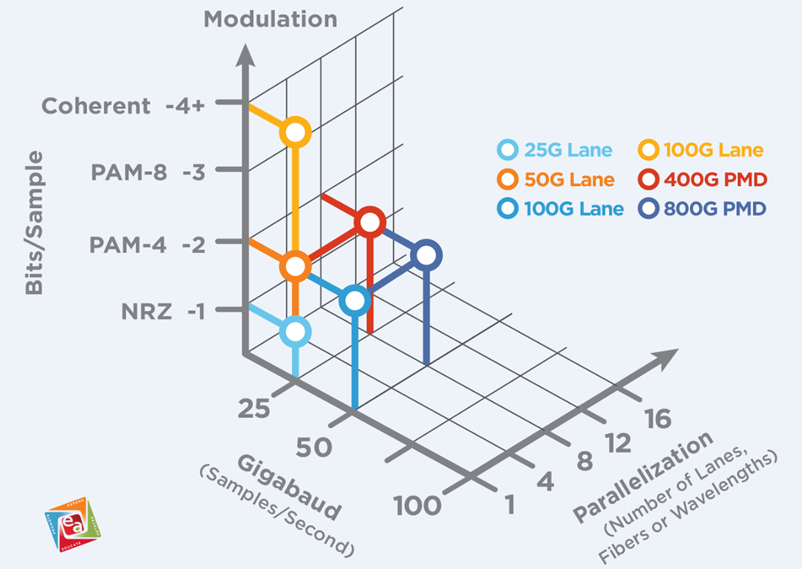
Image : Nombre de canaux et relation 800G (Source : Ethernet Alliance)
Une solution à 16 canaux nécessite généralement deux connecteurs MPO-16 (ou MPO-24) pour une communication full duplex. En revanche, une solution à 4 canaux ne nécessite qu'un seul connecteur MPO-8/12, ce qui simplifie considérablement l'infrastructure. Plus la vitesse de chaque canal est élevée, plus le coût du câblage est faible et plus l'efficacité énergétique par Gbps est élevée.
Moins de latence, plus d'échelle : Reconstruire le réseau d'IA
La latence est un autre obstacle majeur aux performances de l'IA. Dans les grands centres de données, chaque couche de commutation supplémentaire augmente la latence. Lorsque l'on passe à plus de 10 000 GPU, une architecture de commutation à trois niveaux est souvent utilisée, ajoutant potentiellement jusqu'à cinq sauts de commutation - chacunintroduisant une latence qui dépasse de loin celle du support physique (fibre ou cuivre).
Tomahawk 6 permet d'interconnecter directement jusqu'à 512 XPU et peut évoluer pour prendre en charge plus de 100 000 GPU à l'aide d'un réseau Clos à deux niveaux - une architecture de commutation à plusieurs niveaux très efficace couramment utilisée dans les centres de données à grande échelle - basé sur des liens 200G. Par rapport aux conceptions traditionnelles à trois niveaux, cela réduit le nombre de sauts de commutation de deux, ce qui diminue considérablement la latence pour les déploiements d'IA à très grande échelle.

Image : Tomahawk 6 permet une fermeture simplifiée à deux niveaux pour les réseaux de plus de 100 000 GPU (Source : Broadcom)
Nouvelles tendances de câblage pour les centres de données d'IA
Avec l'augmentation de l'échelle et de la complexité technique, le câblage des centres de données d'IA doit évoluer plus rapidement que les centres de données traditionnels. Une infrastructure de câblage flexible et prête pour l'avenir aide les utilisateurs à s'adapter aux changements technologiques rapides sans avoir à réviser constamment l'infrastructure cachée.
Les normes telles que ISO/IEC 11801-5 et TIA 942 soulignent comment le câblage structuré peut prendre en charge les topologies ToR (Top-of-Rack), Spine-Leaf et Mesh, fournissant ainsi une base solide pour des architectures dynamiques et évolutives.
Aginode propose sa solutionLANmarkENSPACEspécialement conçue pour les centres de données de nouvelle génération. Avec quatre avantages fondamentaux, elle aide les centres de données à naviguer en toute confiance dans la transition vers les réseaux 800G et 1,6T.
Aginode ENSPACE

Alimenter la dorsale de câblage prête pour l'IA
- Efficacité supérieure
Prend en charge les connexions fibre à 8 et 16 cœurs. La conception haute densité optimise l'espace et augmente le débit de données. - Évolutivité à l'épreuve du temps
Compatible avec les modules optiques de 100G à 1,6T, il répond à divers besoins et simplifie la migration lors des mises à niveau techniques. - Optimisation des coûts
L'architecture rationalisée et l'installation simplifiée réduisent le coût total de possession (TCO). - Opérations simplifiées
Les systèmes de brassage haute densité réduisent la complexité du câblage et améliorent l'efficacité de la maintenance.
Partager
A propos de l'auteur
